
Most keyword strategy for books is treated as a ranking problem. Generate candidate queries. Score each one on relevance, demand, and competition. Remove the weak ones. Keep the top fifteen or twenty. Ship the list as the book's keyword field.
Keyword tools work this way. Most agencies do too. So do the keyword strategy modules of general-purpose AI systems when handed a book's bibliographic information and asked to produce keywords. The terms produced are usually relevant. The volume estimates are usually defensible. The competition assessments are usually reasonable.
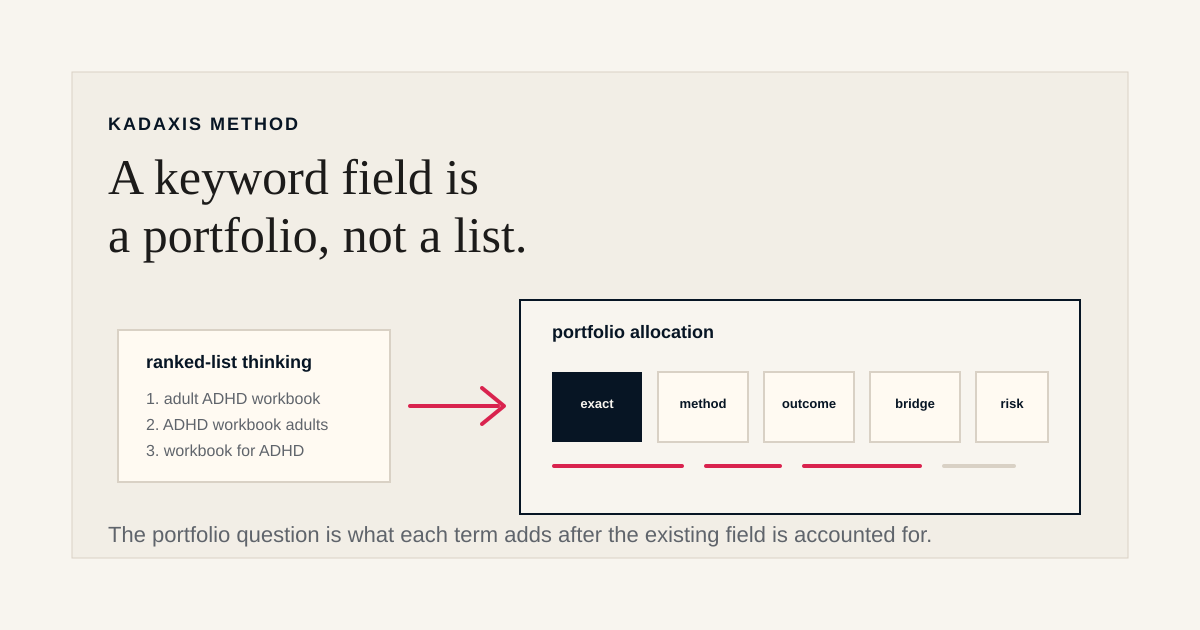
The published portfolio still underperforms, and it underperforms in predictable ways. A keyword field is a limited allocation of metadata space across different ways readers might search for the book.
In this article, a commercial doorway means a query neighborhood that points to a distinct reader intent, result-page pattern, and substitute-book set. A lane means the type of doorway being covered: exact category, product form, audience, method, use case, trope, setting, outcome, or bridge intent. Fifteen individually strong keywords can still crowd into the same doorway, miss important lanes, and introduce risk that no individual keyword score captures.
The portfolio question is different from the keyword question. The keyword question is: "Is this term good?" The portfolio question is: "Given what the field already covers, does this term open a useful new doorway, strengthen an under-covered lane, or merely repeat what is already there?" Answering that question requires a different system from the one that produces a ranked list.
Six ways a portfolio of individually strong keywords can fail
These are the failure patterns we see most often in tool-generated and AI-generated keyword fields. Each failure is a portfolio failure, not necessarily a keyword failure. The individual terms may be relevant, searchable, and defensible. The problem is how they behave together inside a constrained field:
Redundancy failure. The portfolio contains multiple variants of the same commercial doorway: the same basic reader intent, product expectation, and substitute-book neighborhood. Adult ADHD workbook, ADHD workbook for adults, and workbook for adults with ADHD may all score individually well. But if they return broadly similar result pages and serve the same searcher need, three slots have been used to open one door.
Coverage failure. The portfolio misses important reader-intent lanes: different ways a buyer might describe the same need. A workbook may be strongly represented for its exact category and product form but absent from the function-and-outcome lane that many readers actually search (executive function workbook adults, time management workbook). The book could rank for those queries and convert well on them. It cannot, because the metadata never tells the search system to consider it.
Dilution failure. The portfolio includes broad terms that pull the book into wider distributions than it can satisfy. Self-help increases the candidate set's apparent reach and pulls the book into a result distribution where it cannot rank and would not convert if it did.
Bridge failure. The portfolio stays too literal and misses valid customer-intent pathways. A bridge term is a query that does not name the book type directly but still describes a problem, outcome, or use case the book can satisfy. Readers often search for executive function help before they search for an ADHD workbook. A portfolio that names the book's category accurately but omits these bridge terms leaves substantial demand uncaptured.
Over-diversification failure. The portfolio tries to cover too many lanes shallowly. A romantasy spread thinly across general fiction, fantasy, romance, magical realism, and adventure will end up weaker than the same book concentrated on trope and setting lanes (slow burn, enemies to lovers, fae court, morally gray hero).
Wrong-depth failure. The portfolio keeps adding terms in a lane that has already saturated. Once a book has strong coverage for its exact category and product form, the eleventh variant in that lane adds less than the first term in an under-represented lane.
These failures are systematic and predictable. They are also invisible to keyword tools that evaluate terms one at a time. Looking at any single keyword's score will not surface any of them.
Keywords as doors
At the portfolio level, the keyword string is not the unit of value. The commercial query neighborhood behind it is. A keyword is valuable because of the doorway it opens: the searches it can match, the result pages it participates in, the substitutes it is compared against, and the buyer expectation it activates.
For an adult ADHD workbook, the candidate set may include several terms that look semantically similar:
adult ADHD workbook
CBT ADHD workbook
executive function workbook adults
ADHD time management workbook
ADHD emotional regulation workbookA naive semantic deduplication model would collapse most of these because they cluster together in vector space. That collapse loses real commercial information. These terms are semantically close because they all belong near ADHD workbooks, but they do not do the same portfolio job. One names the exact product form, one names the method, one bridges into executive function, one names a time-management outcome, and one names an emotional-regulation outcome.
Redundancy at the portfolio level is governed by commercial overlap. Linguistic overlap is a poor proxy. Two terms with high cosine similarity can open different doors. Two terms with moderate cosine similarity can open the same door. The right deduplication test asks whether two terms cover the same intent lane, the same result distribution, the same reader need, the same product expectation, and the same substitute neighborhood.
This is the first place conventional keyword tools fail. They deduplicate linguistically, which removes diverse terms that serve different commercial functions and preserves terms that are commercially redundant. Both errors produce visibly mediocre published fields.
The lane model
Once candidates have passed the necessary hard gates (product-type fit, relation strength, distributional fit, hard-negative proximity, normalized duplicate collapse), each surviving candidate is classified into one or more commercial lanes.
The lane model stops the portfolio from overbuying one kind of search exposure while ignoring another. It asks: what kind of buyer pathway does this term help cover?
A lane is a commercially distinct way a reader may search for the book. For book metadata, the lanes that matter most often include:
| Lane | Meaning |
|---|---|
| Exact shelf or category | The core commercial category or genre |
| Product form or object | Workbook, novel, textbook, journal, audiobook, large print |
| Audience | Adults, teens, parents, teachers, professionals, beginners |
| Function or outcome | What the reader wants to accomplish |
| Method or framework | CBT, keto, phonics, Stoicism, Montessori |
| Trope or attribute | Enemies to lovers, slow burn, fae, female detective, illustrated |
| Setting or context | Regency, dark academia, classroom, workplace, exam prep |
| Substitute cluster | The comparable-product neighborhood the book belongs to |
| Bridge intent | Customer needs that do not name the book type directly |
| High-consideration research | Complex decisions requiring comparison |
| Behavior-rich anchor | Broader but still relevant head or mid-head queries that connect narrower tail terms to a stable search cluster |
A keyword can belong to multiple lanes. CBT ADHD workbook for adults contributes to product form, method, audience, function-and-outcome, and exact shelf simultaneously. Forcing each candidate into a single lane label, as many simpler systems do, throws away most of the useful signal about what the keyword is actually doing.
Lane weights vary by book. A nonfiction workbook usually needs strong coverage of problem, method, audience, and function. A genre fiction novel usually needs strong coverage of genre, trope, setting, mood, and substitute cluster. A business or technical book usually needs strong coverage of audience, use case, method-or-tool, and high-consideration research. A children's book usually needs strong coverage of age, reading level, use context, theme, and the buyer audience (parent, teacher, librarian) rather than the reader.
A portfolio that allocates lane coverage uniformly across all books is one of the more common failure patterns we see in tool-generated keyword fields. A romantasy and an ADHD workbook require different shapes of coverage. Producing the same shape for both yields uniformly mediocre results across both.
The formal objective
The formal version of the optimization simply turns the editorial judgment above into a selection rule. A good portfolio should reward useful coverage, reward strong individual terms, penalize overlap, and penalize defect risk. The formula below is a compact way to express that trade-off.
The portfolio optimization problem can be stated as:
The components:
| Component | Meaning |
|---|---|
| Portfolio | The set of selected keywords |
| Commercial lane | A distinct buyer pathway the portfolio can cover |
| Lane weight | The importance of that lane for this specific book |
| Coverage function | A diminishing-return curve for each lane |
| Current coverage | The lane coverage already achieved by the portfolio |
| Standalone utility | The individual value of a candidate keyword |
| Redundancy | Pairwise overlap penalty across the portfolio |
| Risk | Penalty for terms that may attract the wrong search intent, product expectation, or substitute set |
The objective is simple. Implementing it requires several models, each of which is its own multi-year problem:
- A lane-weighting model that adjusts lane importance by book type, genre, audience, product form, and competitive position
- A coverage function that saturates at the appropriate rate for each lane (product form saturates quickly with one strong term; trope coverage in fiction saturates much more slowly)
- A keyword-to-lane contribution model that produces multi-lane vectors rather than single labels
- A redundancy kernel that combines semantic similarity, search-result-page overlap, lane overlap, substitute-cluster overlap, and behavior-cluster overlap, with appropriate weighting
- A risk model that catches product-type drift, complement leakage, hard-negative proximity, and broad-parent pollution before they reach the optimizer
The optimizer is the smallest component of the system.
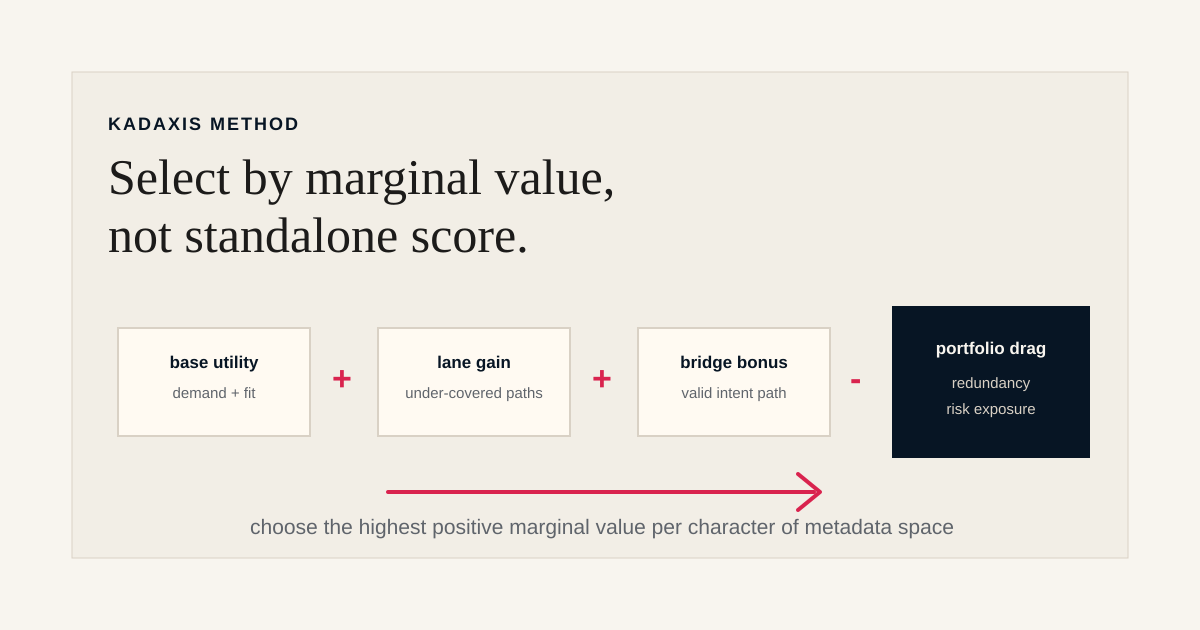
The marginal value selection rule
The selection unit is marginal value given the existing portfolio. An individual keyword's standalone score is one component, but the unit being optimized is the gain from adding a keyword to the current set:
A keyword should be added only when its marginal value is positive.
When there is a fixed budget (and in metadata work there always is, because fields have character and slot limits), the selection rule is:
This frames selection as a greedy submodular optimization. The optimizer picks the highest marginal-value-per-cost candidate at each step, recomputes marginal values for remaining candidates after the addition, and stops when no remaining candidate has positive marginal value or the budget is exhausted.
Integer programming formulations exist and are sometimes worth running on smaller candidate pools. In practice the greedy approach is sufficient and more debuggable. Each component beneath the optimizer requires serious estimation work:
- BaseUtility combines demand, rankability, and relation fit (Exact, Substitute, Complement, Irrelevant probabilities), with the relation-fit terms weighted appropriately and the complement and irrelevant terms penalized rather than rewarded
- LaneCoverageGain measures how much the keyword contributes to each lane, weighted by lane importance for this book, with the diminishing-return coverage function applied
- BridgeBonus measures the value of opening a valid non-literal customer-intent pathway, only when the bridge passes its own admission checks
- RedundancyPenalty is calculated against the existing portfolio's commercial coverage, not against pairwise linguistic similarity
- RiskExposure captures the probability of search-intent defects entering the portfolio through this term
A keyword tool that returns a ranked list is computing BaseUtility and stopping there. Everything that distinguishes a portfolio from a list happens in the other four terms.
Redundancy
Redundancy is where most keyword systems break. The break shows up at the published-field level rather than at the candidate-scoring stage: linguistically similar terms get collapsed when they should remain distinct, and linguistically dissimilar terms get preserved when they are functionally duplicates.
Both errors come from treating semantic similarity as the redundancy test. Semantic similarity correlates with commercial overlap and does not measure it. A linguistically close pair like adult ADHD workbook and CBT ADHD workbook serves different commercial functions. A linguistically more distant pair like workbook for adults with ADHD and adult ADHD self help workbook can serve the same one.
A more accurate redundancy measure combines multiple signals:
where:
- Normalized equivalence captures plurals, token order, and trivial variants
- SERP overlap measures how similar the actual result pages are when both queries are run
- Lane overlap measures whether the two terms belong to the same commercial lanes
- Substitute overlap measures whether the two terms target the same substitute neighborhood
- Semantic similarity is the cosine-style similarity that most tools rely on exclusively
The specific weights and the per-lane adjustments are proprietary. The structural point is that semantic similarity is rarely the highest-weighted component. A redundancy system that leans heavily on it will collapse terms that should remain distinct and will preserve terms that are genuinely redundant.
Bridge keywords
Bridge keywords carry the highest upside in the portfolio. They also carry the highest defect risk. The same candidates produce both.
A bridge keyword is one where the reader does not name the book type directly, but the book is a valid answer to the underlying intent. Executive function workbook adults is a bridge for an adult ADHD workbook. Workflow automation for small business is a bridge for an AI strategy book. Meal prep for muscle gain is a bridge for a high-protein cookbook. Small town female sleuth mystery is a bridge for a cozy mystery.
Bridge terms matter because readers often search by problem, outcome, occasion, or use case rather than by formal category. For some categories the bridge volume exceeds the literal-category volume. A portfolio that omits valid bridges leaves substantial demand uncaptured.
Most portfolio defects also originate in admitted bridge terms that should have been rejected. The same logic that produces a valid bridge can produce a complement-leakage term. Tarot deck fails as a bridge for a fantasy novel involving tarot symbolism, even though the thematic connection is real. Meal planner journal fails as a bridge for a meal-prep cookbook, even though the topical adjacency is obvious. The queries expect a different product object, and admitting them creates measurable defect exposure on the result page.
A bridge keyword passes a separate set of checks before admission:
- Reader typicality. Do readers actually search this way, at meaningful volume, with the intent the bridge implies?
- Substitute fit. Is the book a valid answer to this query, by the same standard the marketplace uses to assess substitutability?
- Result-distribution fit. Does the result page for this query contain books that look like substitutes for this book, or adjacent products and thematically related items?
- Field gap. Does this bridge open a pathway that other portfolio terms do not already cover?
- Complement risk. Does the term imply a different product form (a journal rather than a workbook, a deck rather than a book, a planner rather than a workbook)?
The last check catches the largest share of false-positive bridges. Many semantically plausible bridges imply a different product form, and admitting them produces the same defect class that the hard gates were supposed to filter out at the candidate stage.
A worked example
Take a practical case: an adult ADHD workbook using CBT-style exercises, with content on executive function, time management, procrastination, and emotional regulation.
A keyword tool, asked to produce a candidate set, might return something like this:
ADHD book
adult ADHD book
adult ADHD workbook
ADHD workbook for adults
CBT ADHD workbook
executive function workbook adults
ADHD time management workbook
ADHD procrastination workbook
ADHD emotional regulation workbook
neurodivergent workbook
ADHD planner
anxiety workbook
self helpMost of these have measurable demand. Most are individually relevant. A ranking-based selector would keep the top eight or ten by score.
The portfolio analysis produces a different result.
ADHD book is a broad anchor. It can connect the portfolio to the wider ADHD search cluster, but its result distribution may be wider than this book can satisfy. Admit only if no narrower anchor is available, and only after checking that the marketplace currently surfaces workbooks for the query at competitive positions.
adult ADHD book is broader than workbook. Adds little once adult ADHD workbook is already in the portfolio.
adult ADHD workbook and ADHD workbook for adults open the same commercial door in different surface forms. Keep one. The choice is decided by SERP differences if any exist, otherwise by demand and naming convention.
CBT ADHD workbook opens the method lane. A different door from any other candidate in the set. Keep.
executive function workbook adults is a bridge. The reader does not name ADHD, and the book is a valid answer. The result distribution for this query contains other adult-ADHD-adjacent workbooks. Keep, conditional on the bridge checks passing.
ADHD time management workbook opens a specific outcome lane that the portfolio does not otherwise cover. Keep.
ADHD emotional regulation workbook opens a distinct outcome lane. Keep.
ADHD procrastination workbook opens an outcome lane that partly overlaps with time management. Whether to keep it depends on whether the procrastination result cluster is commercially distinct from the time management cluster in the current marketplace state. That is an empirical question for the optimizer to resolve.
neurodivergent workbook is a broader identity lane with weaker precision. May function as an anchor, may pull the book into a noisier substitute neighborhood. Admit cautiously, after testing.
ADHD planner is product-form drift. The query expects a planner. Reject.
anxiety workbook is an adjacent condition. Reject unless the book's content materially addresses anxiety as a primary topic rather than as a secondary mention.
self help is broad-parent pollution. Reject. If a self-help anchor is needed, replace with a narrowed variant such as ADHD self help workbook for adults, which sits in the self-help lane without the breadth penalty.
A strong portfolio for this book might land at:
adult ADHD workbook
CBT ADHD workbook
executive function workbook adults
ADHD time management workbook
ADHD emotional regulation workbook
ADHD self help workbook for adultsSix terms. The portfolio covers exact product form and audience, method (CBT), the executive-function bridge, the time-management outcome, the emotional-regulation outcome, and a narrowed self-help anchor. It does not cover anxiety, planners, broad neurodivergence, or general self-help. The absent lanes are absent by design.
This is what a portfolio looks like when each term has been admitted by marginal value.
Why this is hard
The algorithm is straightforward. Greedy submodular optimization with appropriate constraints is well understood, tractable to implement, and operationally easy to reason about. The work that requires real expertise is the system feeding it:
- A demand model that distinguishes head, mid-head, and tail traffic accurately enough to make lane-weighting decisions
- A relation-fit model that produces calibrated Exact, Substitute, Complement, and Irrelevant probabilities for arbitrary query-book pairs across many categories
- A distributional-fit model that compares result pages to substitute neighborhoods rather than to semantic neighborhoods
- A redundancy kernel that captures commercial overlap rather than linguistic overlap
- A lane classifier that produces multi-lane vectors with calibrated contribution weights
- A risk model that catches product-type drift, complement leakage, hard-negative proximity, and broad-parent pollution at the candidate stage, before the optimizer ever sees them
- A book-specific lane-weighting model that adjusts portfolio targets by genre, audience, product form, and competitive position
- A bridge admission system that distinguishes valid customer-intent pathways from semantically plausible defects
Each of these is its own modeling problem. Each takes years to build and longer to calibrate against the changing state of the marketplace. The optimizer is the visible layer. The components beneath it are where the actual work lives.
This is the operational reason that keyword fields produced by general-purpose tools, and by general-purpose AI agents asked to do keyword strategy from a book's bibliographic information, tend to underperform in ways that are not obvious until the book has been live for some time and the data has come back. The tool returns a list of individually strong keywords. The published field is a ranked list with the appearance of a portfolio.
A real portfolio for a specific book requires that system underneath: candidate generation, lane weighting, bridge admission, redundancy control, distributional fit, and risk filtering. That is the difference between a list of plausible keywords and a portfolio built to use scarce metadata space deliberately. We have spent fifteen years building that system.