
If you took an average keyword tool and ran it over a publisher's frontlist, it would produce thousands of phrases per book. Almost none of those phrases would do anything for the book's discoverability in retailer search. Some would have no reader demand. Some would not be recognized as relevant to the book by the search engine. Some would duplicate signal the rest of the metadata already supplies. Some would target queries where the book has no realistic chance of ranking. A small minority would survive all four of those tests at once. Those are the keywords that actually do work.
We have written about these failure modes separately in earlier pieces, including whether a keyword adds new signal and the difference between relevance and ranking. This article is the synthesis: a description of the narrow space an effective keyword has to land inside, and why most keyword candidates do not land there.
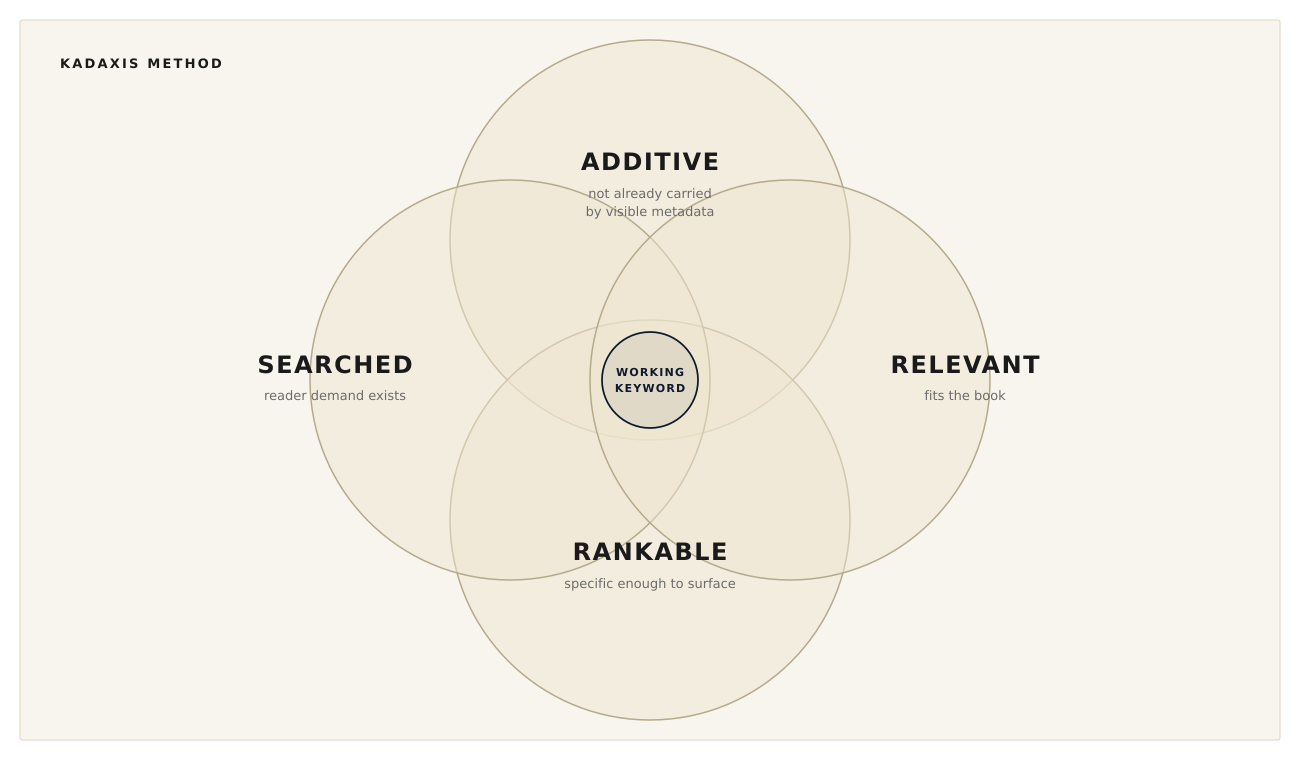
The four tests
The demand test. Someone has to actually be searching for the phrase. A keyword that no reader uses is text in a metadata field, no more. The phrase has to map to a real query that real readers are entering into the search bar. Volume does not need to be high; a long-tail phrase with steady low-volume use can be more valuable than a high-volume phrase the book cannot compete on. But the volume cannot be zero. Phrases that look plausible in a brainstorming session but do not appear in actual reader search behavior are dead weight on the metadata field.
The relevance test. Amazon's search system has to consider the book a plausible answer to the query. This is what we have called semantic eligibility in earlier work. Without it, the book never enters the candidate set the search engine is choosing from. A keyword that sits in the publisher's metadata field but is not understood as relevant to the book by the marketplace is doing no work. Most fiction keyword tools fail this test because they extract keywords from the book's text rather than from the language readers use to search. A dystopian novel does not have characters using the word "dystopia"; a keyword pulled from the text will miss the queries that drive the category.
The non-redundancy test. The keyword has to add evidence the rest of the visible metadata does not already supply. The marketplace already reads the book's title, subtitle, author name, series, description, and category labels. Those fields already send signals to search. If a keyword merely repeats them, it is using the keyword field to say something the rest of the record already says. The marketplace also performs its own associations: a query that names an author can surface that author's other books, a query that names a series can surface the rest of the series, a query that names a popular comp title can surface adjacent titles. Anything the marketplace already infers does not need to be on the keyword field. The keyword slot is most valuable when it carries a relevant association the marketplace would not otherwise make. In our broader analysis, about ninety-two percent of publisher-assigned keywords do not produce visible search results for the assigned book. The largest single reason is that most keyword choices duplicate signal the marketplace already has, which means the keyword is not adding incremental evidence.
The ranking test. Even if a keyword passes the first three, the book has to be able to actually surface for the query at a position a reader will see. Broad queries with very large result sets are dominated by marketplace strength: sales velocity, review counts, recency, advertising, format availability. A book may be semantically eligible for "thriller" but is competing with several hundred thousand other eligible books for that query. Without significant marketplace strength behind it, eligibility alone does not produce visible ranking. Long-tail queries, where the eligible pool is smaller, are where eligibility most directly translates into visible position. The keyword has to be specific enough that the book can actually win the rank competition, given its current marketplace strength.
The tests are simultaneous, not sequential
These four conditions are not a checklist a keyword passes through in order. They are simultaneous requirements, all of which have to be true at the same time. A keyword can fail any one of them and have zero practical effect on the book's discoverability. A keyword can pass three of the four and still produce nothing.
This is why the space of effective keywords is much narrower than the space any one of the tests would identify alone.
A demand-only optimization, which is what most "keyword research" tools produce, generates phrases with high search volume but with no filter for relevance, signal redundancy, or ranking competitiveness. The output is a long list of popular queries, most of which the book cannot rank for and many of which do not match the book's actual content.
A relevance-only optimization, which is what most book-text extraction tools produce, generates phrases that match the book's vocabulary but with no filter for whether readers actually search those phrases, whether the rest of the metadata already supplies them, or whether the book can compete for them. The output looks coherent and is mostly useless.
An incremental-signal optimization without demand filtering generates phrases that are absent from the rest of the metadata but that no one is searching for. Filling the keyword field with these is filling it with text that will never be queried.
A ranking-feasibility optimization without relevance filtering generates phrases that are specific enough to win rank competitions but that may not be relevant to the book at all. A book that "ranks" for a query it should not be in the result set for is a discoverability win on paper and a conversion loss in practice, because readers who click through bounce off a book that does not match what they were looking for.
What this means for keyword strategy
The work of producing keywords that pass all four tests is harder than any one test taken alone. It requires understanding what readers are actually searching for, what the marketplace already knows about the book, what the marketplace is going to associate on its own, and how competitive each candidate query actually is. Most of the keyword tools and workflows in the publishing industry are optimized for one of the four tests and ignore the other three.
The practical implication for a publisher evaluating keyword work, whether internal or vendor-supplied, is to ask which of the four tests the output has been filtered against. If the answer is "we generate high-volume keywords," only one test has been applied. If the answer is "we extract from the book's text," only one different test has been applied. If the answer is "we audit against existing metadata," only one test has been applied. If the answer is "we score for ranking competitiveness," only one test has been applied. None of those is sufficient. The keyword space that has cleared all four filters is small, and the work of getting candidates into it is the actual job.
That space is also where the discoverability gains live. A book with twenty keywords that have cleared four-filter scrutiny will outperform the same book with two hundred keywords that have cleared one filter, by a meaningful margin. The keyword field rewards quality over volume because the field is being read by a search system that is itself filtering for all four conditions before it surfaces a result. The keywords that align with what the search system is already doing are the keywords that work.