
In a recent analysis of publisher-assigned ONIX keywords, only about eight percent produced a visible match in retailer search. The other ninety-two percent did not surface the assigned book in the queries they targeted. The reasons vary, and not all of them are problems publishers can solve. But a meaningful share of that ninety-two percent are keywords that were relevant to the book and that the rest of the metadata already explained. Those are the keywords this piece is about, because they are the ones publishers can do something about.
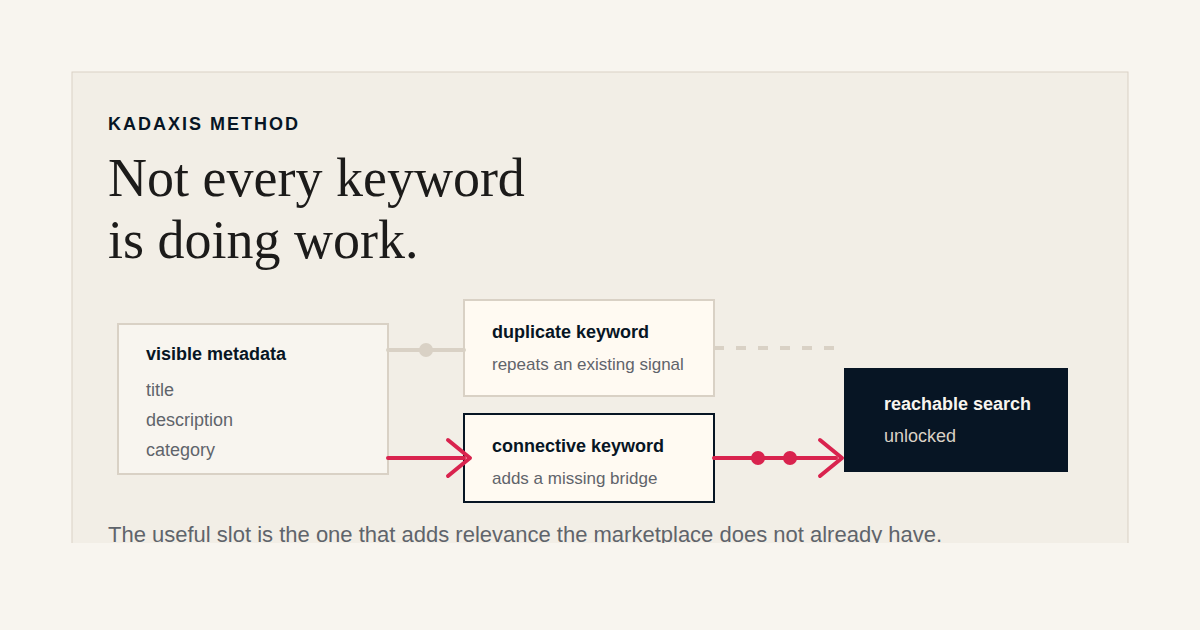
A book's metadata file has a limited number of slots for keywords. The exact character budget varies by retailer and feed standard, but the budget is always finite. The question every publisher faces, whether they think about it explicitly or not, is which keywords to put in those slots. The default approach is to fill the slots with phrases that are relevant to the book. That sounds reasonable. It is also incomplete, and on close inspection it is the source of a lot of wasted keyword space. The reason is that not every relevant keyword is doing the same amount of work. Some keywords add structural signal. Others are decorative. Telling them apart requires a different question than the one most keyword tools and workflows are built to answer.
Consider two cases. A romance novel called The Duke's Last Letter has "regency romance" in its category and a description that talks about ballrooms, dukedoms, and inheritance plots. If a publisher adds "regency romance" as a keyword, what has been added? Almost nothing. The marketplace search system already has overwhelming evidence that this book is a regency romance. The category labels it explicitly. The description is dense with regency-coded language. Even the title's reference to a duke is itself a strong genre signal in this market. Three independent fields all point to the same conclusion before the keyword field is consulted.
Now consider a different romance novel, called The Chestnut Tree, in the same category. Nothing in the title or description uses the word "regency," because the author and editor wanted a more literary register and chose to evoke the period through detail rather than label. The book is genuinely a regency romance. But a reader who searches "regency romance" will not find this book through the title, will not find it through the description copy, and may or may not find it through the category alone, depending on how many thousands of other books share that category. In this case, "regency romance" as a keyword is doing real work. It is creating a relevance association the rest of the visible metadata does not make explicit.
Same keyword. Two books. One use is wasted. The other adds structural signal. The keyword's value is incremental, not absolute.
This is the principle that should govern keyword selection: the value of a keyword is what it adds beyond what the rest of the metadata already establishes. We have written elsewhere about the difference between semantic eligibility and ranking likelihood. This is the next layer down. Within eligibility, not all keyword choices contribute equally to the book's reachable search universe.
There are four rough categories of keyword value, ordered from lowest incremental contribution to highest.
The first is identity repetition. The keyword repeats the title, subtitle, author name, or series name. The marketplace can already match the book to these queries with very high confidence. Adding them as keywords is sometimes done as defensive coverage, but in a finite keyword field, identity repetition consumes space that could be doing work elsewhere.
The second is metadata duplication. The keyword repeats what the description, bullets, or category already say in clear language. A cookbook with "vegetarian Italian recipes" prominently in its description does not need "vegetarian Italian" as a keyword. The marketplace has the signal. The slot would be better used.
The third is broad-category targeting. The keyword targets a query so broad that the result set runs to the tens or hundreds of thousands of books. "Romance," "business," "fantasy," "self help." These queries have too many eligible competitors for any single keyword choice to move the book's visibility much. The book may be relevant. The book is also one of half a million relevant books. Without significant marketplace strength behind it, eligibility for a head term does not produce visible ranking.
The fourth, and the one with the highest incremental value, is what we have started calling connective keywords. These are keywords that target searches the book is genuinely relevant to, that have meaningful search volume, that the rest of the visible metadata does not clearly explain, and that are specific enough to have a manageable competitive set. The reader who searches for "regency romance with literary prose" or "post-war family saga set in northern England" or "leadership books for technical first-time managers" is performing a search the catalogue category and the description copy alone often cannot answer. The keyword field is where that bridge gets built.
Connective keywords are also the hardest category to identify. They require knowing what the rest of the visible metadata already supplies, knowing what the universe of relevant searches looks like, and knowing how those two sets do or do not overlap. A keyword tool that generates phrases without modeling the existing visible metadata cannot produce them by accident. It will produce identity repetition and metadata duplication and broad-category targeting in roughly the volume those things appear in any general keyword corpus, which is most of the volume. The connective keywords get lost in the noise.
The breakdown of the headline eight-percent number is itself instructive on this. Keywords that overlapped strongly with the title or author produced visible matches at much higher rates, often above sixty percent. That is not a vote of confidence in title-overlap keywords. It is a reminder that the marketplace can already identify the book from its title and author. The keyword field is not where that work needs to be done. Keywords in the discovery range, where the visible metadata did not clearly explain the query, produced visible matches at much lower rates, often under three percent. That is harder territory. It is also where the keyword field can do something the rest of the metadata cannot.
The reasons keywords fail to produce visible matches are several. Some are too broad for the book's marketplace strength. Some target queries already saturated by stronger competitors. Some are irrelevant to the book despite being assigned. And a substantial share are relevant keywords that the marketplace can already infer from the title, author, or visible metadata, which means the keyword field is being used to repeat a signal already present rather than to add a signal that was missing. That last category is where most of the recoverable keyword space lives.
The practical implication for a publisher is concrete. Keyword selection should start with an audit of what the rest of the visible metadata already says. The title, the subtitle, the author name, the series name, the description copy, the category selection. Anything the marketplace can already infer from those fields does not need to be repeated in the keyword slots. The keyword slots are for the relevant searches the marketplace cannot infer otherwise.
This is a different workflow than "generate a long list of relevant keywords and pick the highest-volume ones." That workflow tends to produce keyword lists dominated by identity repetition, metadata duplication, and broad-category terms, because those are what bulk keyword tools surface. The workflow that produces connective keywords is harder to automate and produces shorter lists. The lists are also more useful, because every entry is doing work the rest of the metadata is not already doing.
There is one corollary worth naming. A book whose visible metadata is rich and well-written has a smaller useful keyword field than a book whose visible metadata is thin or generic. If the title, description, and category already explain most of the book's reachable searches, the keyword field is left with a narrower set of legitimate connective opportunities. If the visible metadata is undercooked, the keyword field has more work to do. This means keyword strategy and visible-metadata strategy are not separate exercises. They are two halves of the same problem. Improving the description often reduces the keyword field's burden, which frees keyword slots for harder, more specific work that only the keyword field can do.
The summary, which we tell every publisher we work with: keyword space is real estate. The question is not whether each phrase is relevant to the book. The question is whether each phrase is adding relevance the marketplace does not already have. Most of the keyword fields we audit are filled with phrases that fail the second test. Cleaning that out, and replacing it with the smaller set of phrases that do pass the second test, is a meaningful share of what good metadata work actually consists of.