
Amazon accounts for roughly half of US print book sales and around two-thirds of US ebook sales. Surveys consistently show that more US consumers begin their online product searches on Amazon than on any other platform, including Google: estimates range between fifty and sixty-six percent depending on the year and the methodology, but the direction has been steady for several years now. For books specifically, the combination of Amazon's retail dominance and its position as the default starting point for product discovery means that any practical conversation about book discoverability is, in large part, a conversation about Amazon search.
We have written about pieces of this picture in earlier articles: semantic eligibility, the difference between relevance and ranking, and why most keyword fields do not produce visible search results. This piece pulls them together into the full sequence. From the moment a publisher's metadata leaves the warehouse to the moment a reader clicks buy, a book passes through four filters. Each one removes most of the books that reached it. The work of metadata strategy is the work of getting a book through all four.
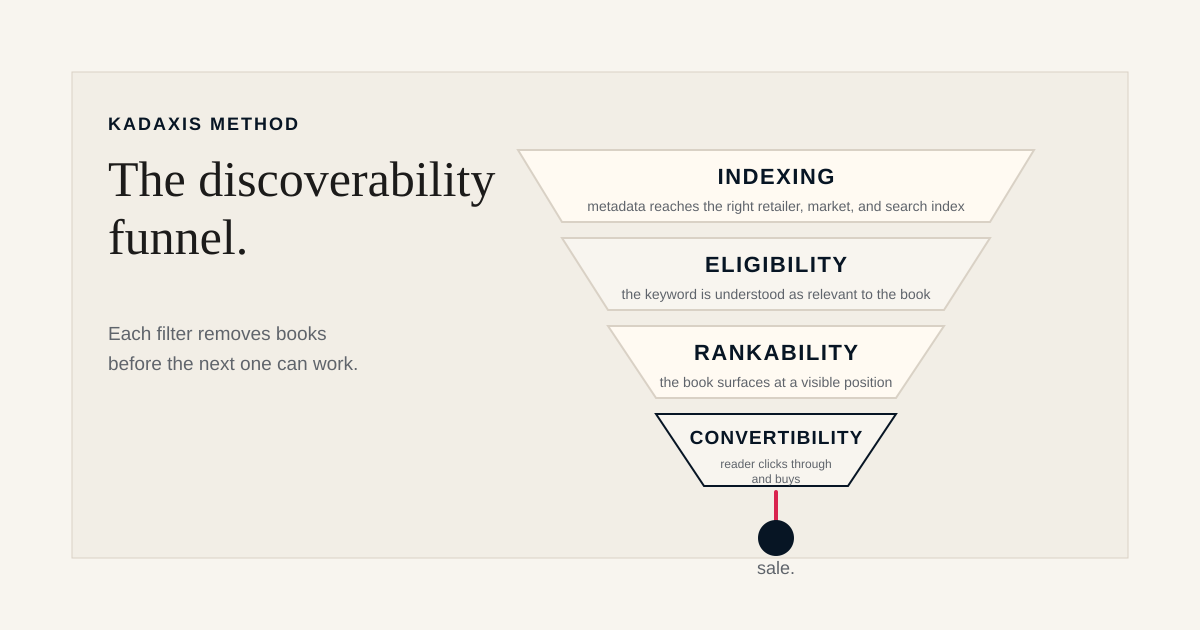
The four filters
In order:
- Indexing. The book's metadata reaches the retailer's search index for the right market and the right product index.
- Eligibility. The keyword the book is targeting is understood as semantically relevant to the book by the retailer's search system.
- Rankability. The book surfaces at a visible position in the result set when a reader runs the query.
- Convertibility. The reader clicks through to the product page and then through to a purchase.
These are sequential. A book that fails at filter one cannot be helped by anything done at filters two, three, or four. A book that passes one and two but fails three is invisible. A book that ranks but does not convert sells nothing. Effort spent optimizing later filters when an earlier filter is broken is wasted effort.
Filter 1: Indexing
The book has to actually be in the index a reader is searching.
ONIX feeds are sent from publishers and distributors to retailers, and each retailer maintains its own indexes. Amazon alone has separate indexes for Books, All, Kindle, and Audiobook. Each market and territory may be indexed differently: the US Amazon catalogue is not the same as the UK Amazon catalogue, and a book available in one market may not appear in another's index at all. Pricing rights, regional availability, format availability, and territorial sales restrictions all affect what gets indexed where.
A lot of the discoverability problems publishers describe to us at the start of an engagement turn out to be indexing problems rather than keyword problems. ONIX errors, missing audiobook feeds, expired pricing windows, or rights conflicts can mean a book is simply not present in the search system being searched. Downstream work is wasted until the book is actually in the index. Before optimizing for any keyword, a publisher needs to verify the book is present in the priority retailers and markets.
Filter 2: Eligibility
Once a book is indexed, the keyword has to be understood as relevant to the book by the search system. This is what we have called semantic eligibility. Without it, the book is in the index but is not in the candidate set the search engine pulls from when a reader runs the query.
We have written about this at length in Not every keyword is doing work. The short version is that keyword choices fall into roughly four categories of value, depending on whether and how they add relevance signal: identity repetition, metadata duplication, broad-category targeting, and connective keywords. The first three categories add little or no eligibility signal because the marketplace either already has the signal (title and author tell it most of what identity repetition would add) or because the keyword is too broad to specify the book among hundreds of thousands of equally eligible candidates. Connective keywords, the small category that adds genuine new eligibility, are the keywords that do work at this filter.
Filter 3: Rankability
Even when a book is eligible, the search system has to choose to surface it at a position the reader will actually see. This is where the marketplace's ranking algorithm weighs the eligible candidates against each other and picks an order.
Two factors dominate that ordering: how closely the book matches the query semantically, and how well the book has been selling. The weight between those two factors shifts with the query, and the shift is what determines which books actually rank.
For short, broad queries (one or two words, large categorical labels like "romance," "thriller," "business," "history"), the eligible candidate pool runs into the hundreds of thousands. Relevance alone cannot order that pool meaningfully because nearly all the candidates are equally relevant. The algorithm leans heavily on sales-based signals: recent sales velocity, conversion rate, review count and rating, recency of publication, and advertising spend. The books that surface at the top of "romance" are not the most relevant romance books; they are the ones that are selling. A new release with no sales history, no matter how well-positioned in metadata terms, will not rank for "romance" against established bestsellers.
For long-tail queries (specific multi-concept phrases, intent-laden language, narrow audience qualifiers), the eligible pool is much smaller. Relevance does more of the ordering work because the algorithm has fewer candidates to choose between. A book with modest sales but strong specific relevance to a long-tail query can surface at the top of the result set. This is where eligibility most directly translates into visibility.
The boundary between the two cases is not clean. Even on a long-tail query, the algorithm sometimes pulls in high-selling books that are not particularly relevant, because the algorithm's bias toward proven sellers can outweigh its bias toward semantic fit. A reader searching for a specific intent will often see a result set that mixes genuinely relevant books at the top with high-selling near-misses interleaved further down. This is a friction every metadata operator runs into: ranking is not purely a function of relevance, and queries with thin result pools sometimes get filled out with high-volume sellers whose only connection to the query is incidental word overlap.
The more important implication, though, is about purchase intent.

A reader who types "romance" is browsing. They have no specific book in mind. They are looking for ideas, possibilities, a list to choose from. Their purchase intent at the moment of search is low; they may click through several results, add things to a wishlist, browse for a while before buying anything, or buy nothing today. A reader who types "regency romance with literary prose for fans of Susanna Clarke" has already done the narrowing themselves. They know what they want. Their purchase intent is much higher. They are closer to a purchase, the click-through rate from search result to product page is higher, and the conversion rate from product page to sale is higher again.
The longest-tail query is the title-and-author search ("the seven husbands of evelyn hugo"). Purchase intent at this point is effectively certain; the reader is going directly to a specific known book to buy it. Keyword strategy is irrelevant at this end of the spectrum because the book's own title and author already identify it. But it is worth naming as the right-hand edge of the distribution.
What this gives us, taken together, is a working picture of which keyword space is worth investing in.
The very short-tail head terms are dominated by sales-based ranking and have low purchase intent. Even if a book ranks for "romance," the reader is browsing, not buying. The return on getting a book to rank for a head term is low unless the book already has the marketplace strength to compete there, which means the keyword work is not where the strength came from.
The middle of the long tail is where eligibility translates most directly into ranking and where the reader's purchase intent is high enough to convert. This is where the connective keyword work pays off.
The longest tail (title and author searches) is outside the reach of keyword strategy entirely.
Most useful metadata work happens in the middle of this spectrum, not at either end.
Filter 4: Convertibility
A book that ranks for a query still has to convert. There are two conversions in this filter, each with its own factors: from the search result page to the product page, and then from the product page to a sale.
From the search result page to the product page.
When a reader looks at a search result page, they see the cover, the title and author, the star rating, the review count, and sometimes a small snippet of bibliographic information. The publisher's keyword strategy is invisible at this stage. What's visible is the work the cover, title, and accumulated social proof have done.
The cover is doing two jobs. It has to signal the genre or category that the reader is searching for (a romance cover should look like a romance cover; a thriller cover should look like a thriller cover), and it has to stand out from the other covers around it on the page. A reader scanning a row of regency romance covers is looking for the one that hits the genre's visual codes most clearly while still being distinctive. A cover that doesn't match the visual codes will not get clicked even if the book is the most relevant on the page. A cover that matches but blends in too thoroughly with its neighbors won't either. Cover decisions made before the book reaches the marketplace are doing significant work at this stage.
The title carries part of the conversion work too. A reader searching for "leadership books for first-time managers" is more likely to click a book titled The First-Time Manager than a book titled Leadership Insights, even if both books are equally good and both rank at adjacent positions. The title's job at the SERP stage is to confirm that this book is the answer to the query the reader typed.
Social proof, in the form of star rating and review count, is the most visible quantitative signal on the search results page. A reader looking at two adjacent books is overwhelmingly more likely to click the one with twelve hundred reviews at four-point-five stars than the one with fourteen reviews at four-point-two stars, even if the books are otherwise comparable. Social proof is a conversion factor independent of all the others, and it compounds: more clicks lead to more sales lead to better rankings lead to more clicks.
From the product page to the sale.
Once the reader clicks through, a different set of factors takes over. The visible metadata on the product page becomes critical: the full title and subtitle, the description copy, the bullet points, the author bio, the look-inside sample, the format options, the price, and the comp titles in the "customers who bought this also bought" panel.
The description is doing most of the conversion work. A description that opens with a strong hook, signals the reading experience accurately, and matches the language of the search intent the reader expressed is converting at a higher rate than a description written in trade-catalogue voice. We have written elsewhere about the gap between catalogue voice and reader voice; that gap is most expensive at the product-page stage, because the reader is closest to the buy decision and the wrong register loses them.
The look-inside sample is the highest-fidelity preview a reader gets before buying. For fiction, the opening pages do work the description cannot, signaling whether the book actually delivers the experience the description promised. For non-fiction, the table of contents and a few sample pages let the reader verify that the book covers what they need. A sample that doesn't match the description's promise is a conversion killer at exactly the moment the conversion is being decided.
The "customers who bought this also bought" panel is the marketplace's own associative work, and it cuts both ways. Strong comp titles in that panel can drive sales by extending the reader's interest. Weak or wrong comp titles position the book among the wrong neighbors, which subtly tells the reader they are in the wrong place, and the sale is lost.
Why the funnel has to be thought of as a whole
The filters compound. A book that passes indexing, eligibility, and ranking but fails at the cover or the description does not sell. A book that has a strong cover and strong reviews but never ranks does not sell either. Investments at any one filter are limited by the weakest filter upstream of it. Keyword strategy by itself does not move performance unless the rest of the funnel is also functioning.
This is the case for treating metadata work as one piece of a larger system. Keywords are the work at filter two and have some influence at filter three. They have no direct effect on filters one or four. A publisher who invests heavily in keyword optimization while neglecting cover design, description quality, sample text, or review accumulation is optimizing the early stages of a funnel whose later stages still leak.
The publishers we see produce the strongest results from our work are the ones who treat the funnel as a single connected system. They get the metadata right because that is where we focus, and they also get the cover right, the description right, the sample right, the pricing right, and the review-acquisition strategy right. Each filter's optimization compounds the next. Each leak anywhere in the funnel is a leak everywhere downstream of it.
That is the version of the work that produces durable results. Anything narrower is partial.